



Fermi技术细节抢先预览
 面对RV870的咄咄逼人,目前
面对RV870的咄咄逼人,目前
NVIDIA尚欠缺能与之匹敌的产品。但
NVIDIA下一代DirectX 11 GPU(代号为Fermi)即将于今年底或明年初上市,届时真正的DirectX 11大战才开始。笔者有幸提前洞悉了Fermi架构的部分资料,我们不妨一起来看看Fermi架构究竟做了哪些改进?
在开篇需要说明的是,目前笔者了解的主要还是Fermi架构的GPU
Computing部分的概况,而像纹理单元、光栅单元等方面的改进,NVIDIA仍是闭口不谈。这并不代表Fermi在图形处理方面没有建树,只是NVIDIA希望产品在正式发布的时候才公开这部分内容。因此,本文主要的内容将围绕Fermi架构的GPU Computing概况展开。
从GPGPU到GPU Computing
如今,T&L处理已经不再由GPU内的固定功能单元完成,而是由完全可编程的统一着色器单元来执行。GPU承担了几乎整个图形渲染流程并且开始在更多由CPU执行的传统任务中扮演重要的角色,例如从2003年开始,在诸如蛋白质折叠、SQL 查询、核磁共振成像重建等具备并行运行特性的计算领域内有了GPU的身影。
当时的GPU仍然使用DirectX、OpenGL这样的图形API来完成非图形计算的应用,这被称之为GPGPU。虽然GPGPU证明了GPU在通用计算上有很大潜力,但这要求程序员必须了解这些图形API和GPU体系结构的知识,求解的问题需要采用顶点坐标、纹理、着色器程序等图形术语来描述。虽然后来斯坦福大学提供了Brook这种高级的GPGPU语言,程序员基本上不需要学习图形学上的概念,但Brook实际上还是基于3D API,只是可以使用类似C语言来编写程序,然后经Brook可以转换成OpenGL GLSL和D3D HLSL。因此Brook虽然简化了GPGPU 的学习过程,但是功能上就受到3D API的约束,诸如像可定址的读操作/写操作等基本的编程特性无法支持,导致编程模型受到很大的约束。
2006年,NVIDIA借发布G80的机会,推出名为CUDA的通用计算架构。CUDA由硬件和软件两部分组成。硬件指的是G80及其衍生的硬件架构;软件指的是CUDA C编译器以及围绕硬件架构开发的的各种工具。通过CUDA的扩展工具,程序员可以直接为针对通用用途的大规模并行处理器编写程序,而不是通过图形API给图形处理器编写程序。对于这种先进的编程模型,NVIDIA称之为GPU Computing。
和G80体系结构参照著名物理学家姓氏命名为Tesla一样,NVIDIA下一代DirectX 11 GPU的体系结构也采用了另一位知名物理学Enrico Fermi(恩里科.费米)的姓氏Fermi来命名。在G80架构的基础上,Fermi架构有重大的跃进,主要体现在性能和可编程性方面的扩展。
和Fermi架构息息相关——CUDA编程模型的原理
理解CUDA编程模型的原理有助于我们进一步认识Fe rmi架构。CUDA由硬件和软件架构共同组成,即必须在支持CUDA的NVIDIA GPU上,利用CUDA C语言编译器以及围绕NVIDIA GPU开发的各种工具才能进行CUDA计算。这个架构可以让NVIDIA GPU执行由C、C++、Fortran、OpenCL、DirectCompute以及其它语言所编写的程序。
在GPU内执行的CUDA程序被称作并行kernel,kernel是通过一系列平行、互不依赖的Thread(线程)以并行的方式来执行。GPU会将一个kernl程序模拟成一个由若干个Thread block(线程块,由Thread组成,Thread block=512Thread)组成的Grid(线程块格)。

在CUDA的编程模型中,Warp、Thread、Thread block和Grid是很重要的
在CUDA中,每个Thread 都有一块per-Thread private memory的私有空间又被称作 local memory),用于寄存器溢出、函数调用(function call)。每个Thread Block都有自己的一块per-block shared memory空间,用于Thread Block内线程间的通信、数据共享以及并行算法中的中间结果共享。
Thread、Thread block和Grid之间的关系
在执行kernel程序时,很有可能需要进行Thread之间的共享、临时数据交换。为了实现高效的Thead 共享、临时数据交换,就必须将一堆Thread组织起来,这个组织起来的单位就是Thread block。
Thread Block指的是能通过障栅同步和Shared memory彼此协作的一组并发执行线程。在G80和GT200中,每个Thread Block多拥有512个并发线程。而在Fermi中,每个Thread Block多可以有1536个并发线程。在Grid中,每个Thread Block都有自己的ID。
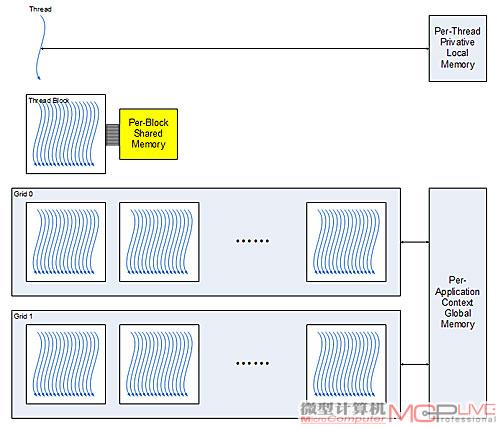
Thread是组成Thread block和Grid的原始单位
在Thread block内,每个Thread执行kernel内的一个instance(实例,例如一个像素或者像素中的一个色元等),每个Thread 都有自己的Thread ID、program counter(程序计数器)、register(寄存器)、per-Thread private memory(逐线程专有存储器)、input(输入)以及output result(输出结果)。
Grid就是一个由多个Thread block组合而成的矩阵,需要从Global Memory中读取Input以及往Global Memory中写入结果。
核心才是关键——第三代Streaming Multiprocessor
虽然在CUDA的概念里,CUDA Core或者Streaming Processor内核(简称"SP")指的就是一个处理核心。但其实SP只是一个功能单元,真正比较接近于我们常说的内核则是SP的上一级单位——Streaming Multiprocessor(简称"SM")。因为目前只有在SM这一级才具备Program Counter(程序计数器)、调度资源以及分离的寄存器堆块,即才能进行CUDA计算。在AMD统一着色器架构的GPU中,类似SM等级的部件是SIMD Core,例如RV870拥有20个SIMD Core。
双精度计算的好处
双精度计算能力直接决定了线性代数、数值模拟、量子化学等高性能计算(HPC)应用程序的执行效率,Fermi为此进行了专门的设计,提供了前所未有的双精度性能——一个SM每周期能执行高达16个双精度的FMA指令。
按照NVIDIA透露的初步资料,第一款Fermi架构的GPU将会有16组SM,每一组SM包含了32个SP,每个SP都有全流水线化的整数算术逻辑单元(ALU)和浮点单元(FPU)。ALU支持64bit和扩展指令,支持算术、shift(位移)、Boolean(布尔)、comparision(比较)以及move(数据传输或者赋值)。

第一款Fermi GPU的体系结构图
虽然Fermi的SM数量从GT200的30个下降为16个,但SP总数却达到了512个(GT200为30×8=240个),实际的单周期理论性能则提升了近1倍甚至更多(例如双精度浮点运算)。
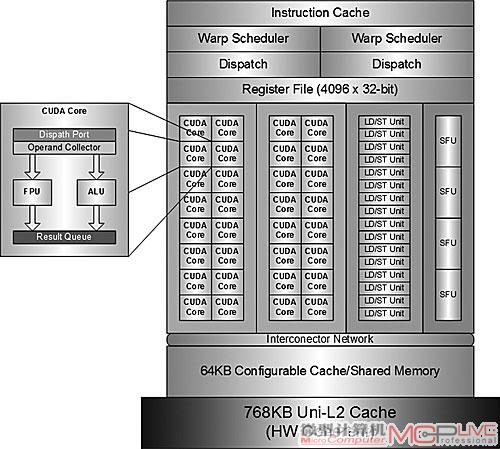
一组SM包含了32个SP
另外,一个SP每个周期可以实现一个Thread的一条浮点指令或者整数指令;该GPU上有六块64bit的内存分区,能提供384-bit的内存数据总线,可以支持多达6GB甚至更多的GDDR5内存。
好事成双——Dual Warp Scheduler(双Warp调度器)
按照NVIDIA的说法,Fermi的SM拥有两个Warp Scheduler(简称"DWS")和两个指令分发单元,允许两个Warp同时发射和执行。DWS会挑选出两个Warp并对每个Warp各发射一条指令到不同的执行块。NVIDIA并没有具体透露这里的“执行块”是什么,笔者估计可能是指SM中的SP被划分成若干个组或者是不同的指令执行端口。在CUDA的并行编程模型下,大多数的指令都能实现双发射,例如:两条整数指令、两条浮点指令或者整数+浮点的组合。

一个SM具备两个DWS
什么是Warp?
Warp是SM的处理宽度,或者说是SM的SIMD宽度。每次指令发射,都是以一个Warp为一个单位,G80和GT200发射一次指令执行一个Warp,一个Warp需要4个周期。
数据交换的法宝——灵活多变的Shared memory和L1/L2 Cach
每个SM里面拥有一个容量很小的内存空间,即Shared Memory,可以用于数据交换,程序员可以方便自由使用。有了Shared memory后,同一个Thread block内的线程可以共享数据,极大地提升了NVIDIA GPU在进行GPU Computing应用时的效率。
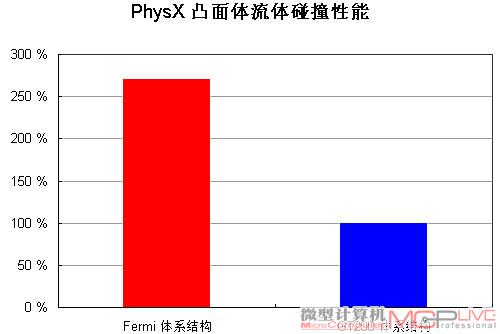
Fermi的Cache设计对物理算法例如流体模拟来说有莫大的好处,
在PhysX凸面流体碰撞放运算方面,Fermi的性能大幅领先GT200。
虽然Shared memory对许多计算都有帮助,但它并不适用于所有的问题。佳化的内存层次架构方案就是同时提供shared memory和cache,Fermi就采用了这样的设计。在G80和GT200中,每个SM都有16KB的Shared memory。而在Fermi中,每个SM拥有64KB的Shared memory,能配置为48KB Sharedmemory+16KB L1 cache或者16KB Shared memory+48KB L1 cache的模式(G80和GT200不具备L1/L2 cache)。程序员可以自己编写一段小的程序,把Shared memory当成Cache来使用,由软件负责实现数据的读写和一致性管理。而对那些不具备上述程序的应用程序来说,也可以直接自动从L1 Cache中受益,显著缩减运行CUDA程序的时间。
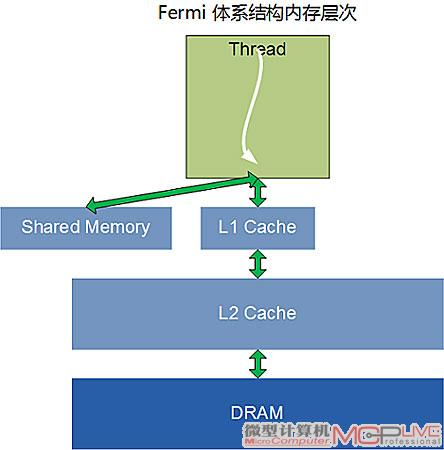
L1/L2 Cach是Fermi的内存层次系统中的创新设计
过去,GPU的寄存器如果发生溢出的话,会大幅度地增加存取时延。有了L1 cache以后,即使临时寄存器使用量增加,程序的性能表现也不至于大起大落。
另外,Fermi提供了768kB 的一体化L2 cache,L2 cache为所有的Load/Store以及纹理请求提供高速缓存。对所有的SM来说,L2 cache上的数据都是连贯一致的,从L2 cache上读取到的数据就是新的数据。有了L2 cache后,就能实现GPU高效横跨数据共享。对于那些无法预知数据地址的算法,例如物理解算器、光线追踪以及稀疏矩阵乘法都可以从Fermi的内存层次设计中显著获益。而对于需要多个SM读取相同数据的滤镜以及卷积核(convolution kernel)等算法同样能因为这个设计而获益。
为并行处理而生——第二代PTX指令集架构
PTX是NVIDIA针对支持并行线程处理运算而设计的低级虚拟机和ISA指令集。当程序执行之前,PTX指令会被GPU驱动转译为GPU的本机代码。此次,NVIDIA特别强调Fermi是第一个支持PTX 2.0的体系架构,而G80则是PTX 1.X。
高度整合——统一寻址空间
在PTX 1.x中,当load/store指令被执行的时候,需要指定三个寻址空间中的其中一个,程序才可以在编译时确定指定寻址空间中的load/store 数值。这样的计算能力很难提供完整的C和C++指针,因为在编译过程中很难确定一个指针的目标寻址空间。而PTX 2.0则实现了统一寻址空间,把三个寻址空间都统一为一个单独、连续的寻址空间。
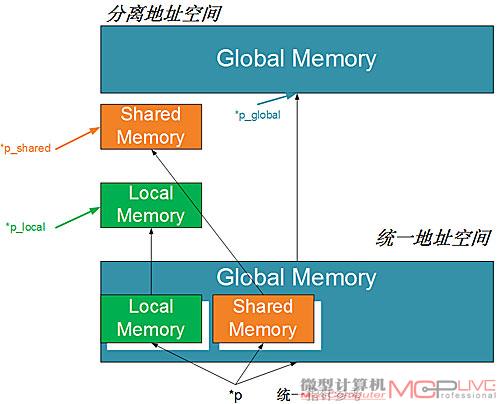
有了统一寻址空间以后,就只需要一组Load/Store指令
因此只需一组Load/Store指令,而不再需要三套针对不同寻址空间的Load/Store指令。此外,PTX 2.0还增加了C++虚拟函数、函数指针,针对动态分配对象、解除分配的“new”和“delete”操作以及针对异常处理操作的“try”和“catch”。
针对OpenCL和DirectCompute的优化
OpenCL、DirectCompute与CUDA的编程模型有非常密切的对应关系,CUDA里的Thread、Thread block、Grid、障栅同步、shared memory、global memory以及原子操作都能在OpenCL和DirectCompute中看到,因此基于Fermi的GPU在运行OpenCL和DirectCompute时会更加得心应手。此外,Fermi架构还为OpenCL和DirectCompute的表面(surface)格式转换指令提供了硬件支持,允许图形与计算程序能简单地对相同的数据进行操作。同时,PTX 2.0还为DirectCompute提供了population count、append以及bit-reverse指令的支持。
浮点运算好帮手——支持IEEE 754-2008规范
在浮点运算方面,G80、GT200的单精度运算都是采用IEEE 754-1985标准的浮点算法,Fermi在单精度浮点指令上提供了对次常数(subnormal number,即denormal number或者denormalized number)以及IEEE754-2008标准的所有四种舍入模式(nearest、zero、positive infinity、negative infinity)的支持。
什么是次常数
次常数指的是在定浮点数系统中分布于小正数和大负数之间的数。小正数和大负数取决于系统的设定。假设大负数是-1,小正数是1,在-1和1之间的数就是次常数。
面对次常数,CPU通常将其视作异常情况,会以软件方式进行计算,这需要消耗数千个周期。而过去GPU针对次常数的应对措施并不多,一般GPU会将这个范围内的数据冲刷成零,但会导致精度的损失。而Fermi的浮点单元能以硬件方式处理次常数,允许它们逐渐下溢至零而不至于导致精度的损失。在电脑图形、线性代数和科学应用中常见的运算操作是把两个数相乘,然后将获得的结果与第三个数相加,例如C=A×B+C。以往的GPU会使用multiply-add(MAD)指令来实现上述运算。不过MAD指令中在进行乘法计算(例如 C=A×B+C中的A×B)的时候容易出现一些非常小的尾数。尾数会被切掉,并在接下来的加法运算中使用“舍入到近偶数”的方式作舍入操作。
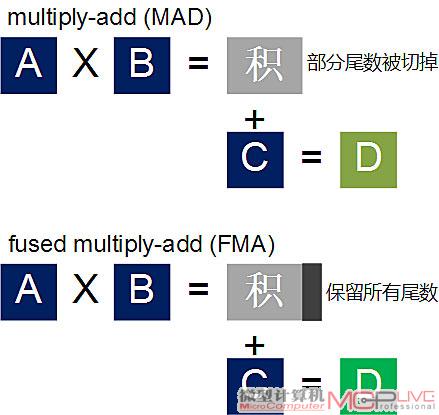
FMA指令可以避免精度的损失
无论是32-bit运算还是64-bit运算,Fermi均使用fused multiply-add(FMA)指令来执行(GT200只对64-bit运算采用FMA指令),可以保证乘法运算的结果以全精度的形式保留。和MAD(multiply-add)指令相比,FMA指令在做乘法和加法运算时只在末做一次四舍五入,不会在执行加法的时候就出现精度损失。提升精度可以让多种算法获益,例如精密的交叉几何体渲染、迭代数学方面的高精度计算以及快速准确舍入的除法与平方根操作。
智能追踪——predication论断
PTX 2.0为所有的指令提供了predication(论断)支持,这会提升执行效率。在采用分支指令执行"if-else(如果-否则)"条件语言的时候,SM必须了解哪些线程在条件中的什么路径中执行;当有额外的分子路径发生时(taken),硬件都会跟踪一组,这会增加线程组。但当条件语言使用论断的话,就能比分支指令更有效,因为只有那些符合的条件测试线程才会被写入到目标寄存器中,其它的线程不会发生改变。
底层的革新——内存子系统特性的变化
服务于HPC市场——第一颗支持ECC技术的GPU
对一般的游戏来说,色彩数据值的一个位元或者多个位元出现错误并不会对游戏产生多大的影响,但是在诸如气象模拟、石油勘探和地震监测等HPC的应用中却可能会造成重大危害。辐射可能会导致内存中的某些数据受到影响,从而产生一个软错误。
ECC技术可以在这些单个位元的软错误对系统产生影响之前就侦测到这些错误并予以修正,因此ECC已经是大规模集群设备必不可少的技术。GT200虽然可以支持双精度浮点运算,但是由于缺乏ECC的支持,实际上并没有在HPC市场中有重大的建树。而Fermi的寄存器堆、shared memory、L1 cache、L2 cache以及DRAM内存都受ECC技术保护,使得Fermi有望成为HPC应用方面性能强大的GPU。
高优先等级——快速原子内存操作
原子内存操作对于并行编程是非常重要的,它可以让并发线程正确地在共享数据结构上执行“读取→修改→写入”操作。像add、min、max以及compare-and-swap这类原子内存操作的优势在于它们在执行读取、修改以及写入操作时不会被其它线程中断。原子内存操作广泛应用于排序(sorting)、归约操作(reduction operation)应用中,甚至可以在非锁定(锁定会导致线程执行串行化)情况下以并行方式建立数据结构。
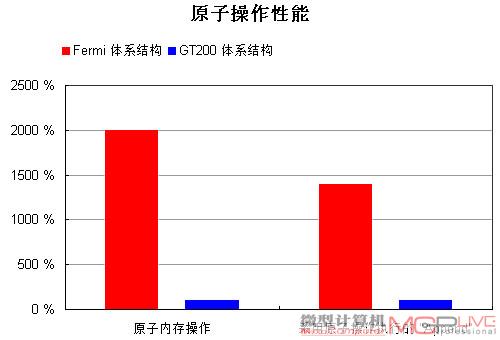
Fermi的原子内存操作能力大大领先GT200
得益于更多的原子操作单元以及L2 cache,Fermi的原子内存操作性能相对以往的架构来说得到了巨大的提升。对同一地址的原子内存操作,Fermi的运算速度是GT200的20倍,而对相邻内存区域的操作则达到7.5倍。
什么是原子内存操作?
原子内存操作是一个不能被其它线程干扰的操作。例如要把一个数据写到一个地址a里,在多线程中,可能有很多个线程都想对地址a进行操作(读、写、修改等),原子内存操作就是必须待这个原子内存操作完成后,其它线程才能对这个地址进行操作。
掌控全局——GigaThread 3.0线程调度器
双层线程分配调度器设计是Fermi重要的技术之一。在SPA(Streaming Processor Array,流式处理器矩阵)里面,有一个全局工作分配调度器(global work distribution engine),它负责将Thread block排程分发给SPA中不同的SM。而SM里面的两个Warp调度器则负责把32线程一组的Warp分配到合适的执行单元。
基于第一代GigaThread引擎的G80能实时管理多达12288个Thread,而在Fermi上不仅线程总数增加了一倍,还提升了context switching(上下文切换)的性能。
应用程序上下文切换——十倍速度
和CPU一样,GPU也可以利用上下文切换(Context Switching)来实现支持多任务(multi-taksing)操作。Fermi的流水线架构已经针对应用程序的上下文切换进行了优化,切换的时间被缩短到10毫秒~20毫秒,较以往的GPU来说有显著的提升。

FMA指令可以避免精度的损失
除了性能的提升,上下文切换还允许开发人员开发出进行频繁kernel-kernel间通讯的应用程序,例如在图形渲染应用程序和计算应用程序之间进行细粒度的互操作。
提升多任务效率——Concurrent Kernel Execution(并发核心执行Kernel)
Fermi首次实现了并发核心程序执行(Concurrent kernel execution,以下简称"CKX"),可以让GPU在同一时间执行同一个程序的上下文的不同核心程序。CKX可以让程序执行多个小kernel,从而充分利用整个GPU。例如一个物理程序可能包含了流体解算器和刚体解算器,如果串列执行的话,只能用到一半的线程处理器,而CKX就可以避免这个问题。不同程序上下文的kernel之所以能够非常高效地串列执行,是因为上下文切换速度得到了改善。
总结:为GPU Computing而生
如果以GeForce 256为起点,GPU发展至今已经有10个年头。在这10年间,GPU架构发生了许多变化。如果说GPU的出现是为了让CPU从TnL计算中释放出来,那么从G80开始我们可以认为,业界正试图把更多的计算负荷从CPU转移到GPU上来,例如物理现象模拟、影像合成、科学计算,即NVIDIA提倡的GPU Computing,GPU开始承担更多的任务。
G80引入了实现线程间共享的Shared Memory(共享式内存)和barrier同步能力;引入了让不相依的多个线程同时执行单个指令的SIMT(单指令多线程)执行模型。G80奠定了GPU Computing应用的基石,而GT200则是在此基础上的增强,它使得寄存器数量倍增,实现了内存存取操作合并,支持硬件双精度浮点运算。到了Fermi,则是代表着GPU Computing在硬件架构和编程模型上已经进入成熟而完备的阶段。
与单纯地增加功能单元的做法相比,Fermi的设计团队解决了若干个GPU Computing方面棘手的难题。在Fermi架构上,数据局部性的重要性通过L1/L2 cahce得以展现;强大的并发式kernel执行让GPU执行多任务能力达到了空前的水平;显著加强的双精度浮点性能设计让GPU达到超级计算机的性能水准。后,Fermi还支持ECC技术,这从硬件架构上扫清了NVIDIA GPU进入HPC市场的障碍。NVIDIA表示,基于Fermi的显卡会在今年底或者明年初上市,价格取决于届时NVIDIA面临的竞争态势。
用户评论
-
-
-
事实上NV现在是不是技术的成功者也值得探讨。N和A的架构孰优孰劣只能透过实际检验来衡量,事实上如果所有的测试或者游戏都关闭了优化的元素之后,两家厂商的芯片性能其实一直是在伯仲之间。 Fermi的架构看图的确很吸引人,但是NV忘了一样东西,那就是想象可以无限大,但是后却都只能立足于一片小硅片之上。随着GPU功能的复杂化,制程的更新已经明显跟不上,Fermi迟迟不能生产就是好的例子。NV继续坚持大芯片的道路现在看来无疑是错误的。 事实上NV的确很厉害,它拥有一大堆自有标准,例如PhysX和CUDA。它的确一呼百应,一大堆THE WAY游戏就是证明。但是,今天的NV和当初的3dfx何其相似,抱着自有的标准,做着黄粱美梦。事实上,任何的标准都可以有替代品。当年DirectX替代了GLIDE,今天同样Direct Computing和OpenCL可以替代CUDA和PhysX。希望NV还是要踏踏实实做好芯片的研发,不要以为自有标准是万能的。所谓的合作伙伴都是商人,商人是唯利是图的,当年他们可以抛弃3dfx,今天就可以抛弃NV。
-
-

